Case Study
1 Introduction
When building from idea to proof-of-concept, the development of a web application may be slowed by technical challenges unrelated to the core concept.
For developers aiming to rapidly prototype web applications and release them to users, the server-side deployment process can often become a time-consuming obstacle. That’s why we developed Tinker: a framework that automates the creation and configuration of backends. Additionally, it offers a dashboard UI which simplifies working with a backend’s database.
This case study will first examine the deployment and configuration challenges that software developers face when developing web applications and the services available to offload some of those concerns. Next, we’ll examine how Tinker tackles some of those challenges and fits into the broader landscape of other solutions. We’ll also look at the components that make up Tinker’s architecture, the decisions that drove us there, and the challenges we faced during its development.
2 Web App Architecture
2.1 Traditional Three Tier
The traditional architecture for web applications consists of a frontend, backend, and a database. The frontend is often referred to as the "presentation layer" of the application, meaning that it facilitates interactions between the client (usually a web browser) and the application backend. Display, button-clicks, keyboard entry - these are all common interactions handled by the front end.
The backend of a web application includes the database, assuming the application requires data to persist. The frontend issues a request to the backend, which then processes the request and returns an appropriate response. During the processing of the request, the backend may interact with the database to manage data storage and retrieval depending on the content of the client request. Any modifications made to the data by the user on the frontend interface, i.e., deleting an item, must be processed through the backend.
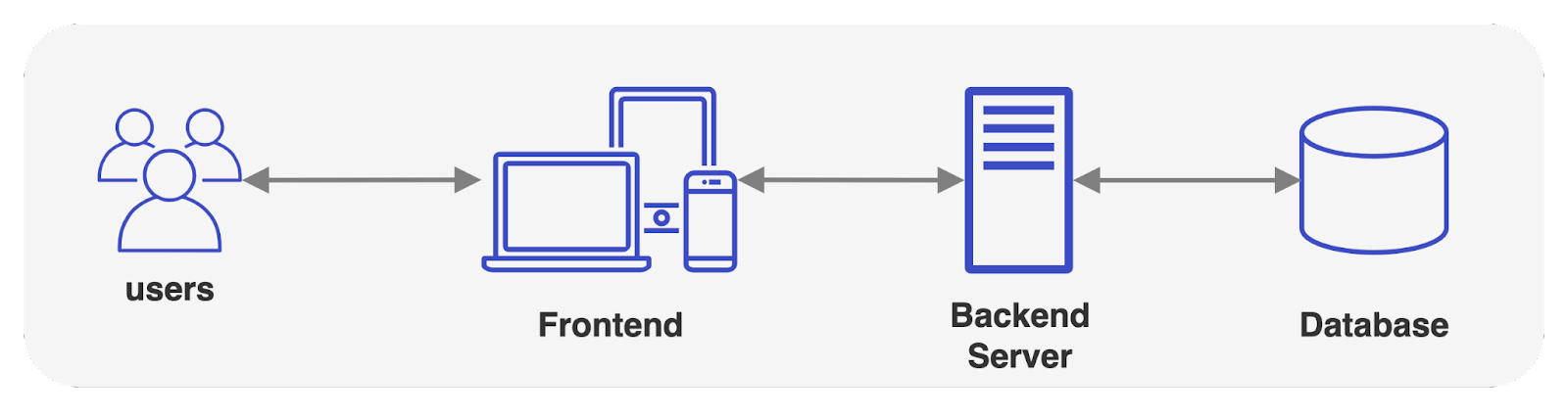
During the initial stages of web application development, developers may host the application on their local machines. The developer iterates over the application until they believe it is production-ready and then must deploy it to be accessible via the Internet.
Even for a simple application, this process involves setting up a web server and possibly a database, which involves dealing with various technical configurations, dependencies, and settings. Developers focused on building the client-side of the application may find this process time-consuming and mentally taxing due to the plethora of steps involved, diverting their attention from the primary client-side features. Additionally, developers who are not familiar with the technologies involved may face a steep learning curve.
During the prototyping phase, developers often go through a cycle of building and discarding initial prototypes. The primary focus during this phase is on iterating and refining the application's core features.
In addition, developers often need to share the application with non-technical stakeholders, such as product managers and business partners, to gather feedback and engage in discussions. Making the application publicly available on the web provides a convenient way for these non-technical stakeholders to access and review it, rather than residing on the developers’ local machine.
For instance, while developing Tinker, we initially had to set up the hosting infrastructure on AWS manually. While these technical aspects were necessary, our main focus was ultimately on creating a dashboard which constituted the core of the application.
2.2 Infrastructure-as-a-Service (IaaS)
When the application is ready for deployment, software developers have options on how to deploy the backend to a server.
One approach is to use "on-premise" servers, where server equipment and space are owned and managed by the company itself. This approach is more feasible for companies that have dedicated IT staff who are responsible for managing server infrastructure. Having control over the servers provides advantages such as data security compliance and fine-tuned customization.
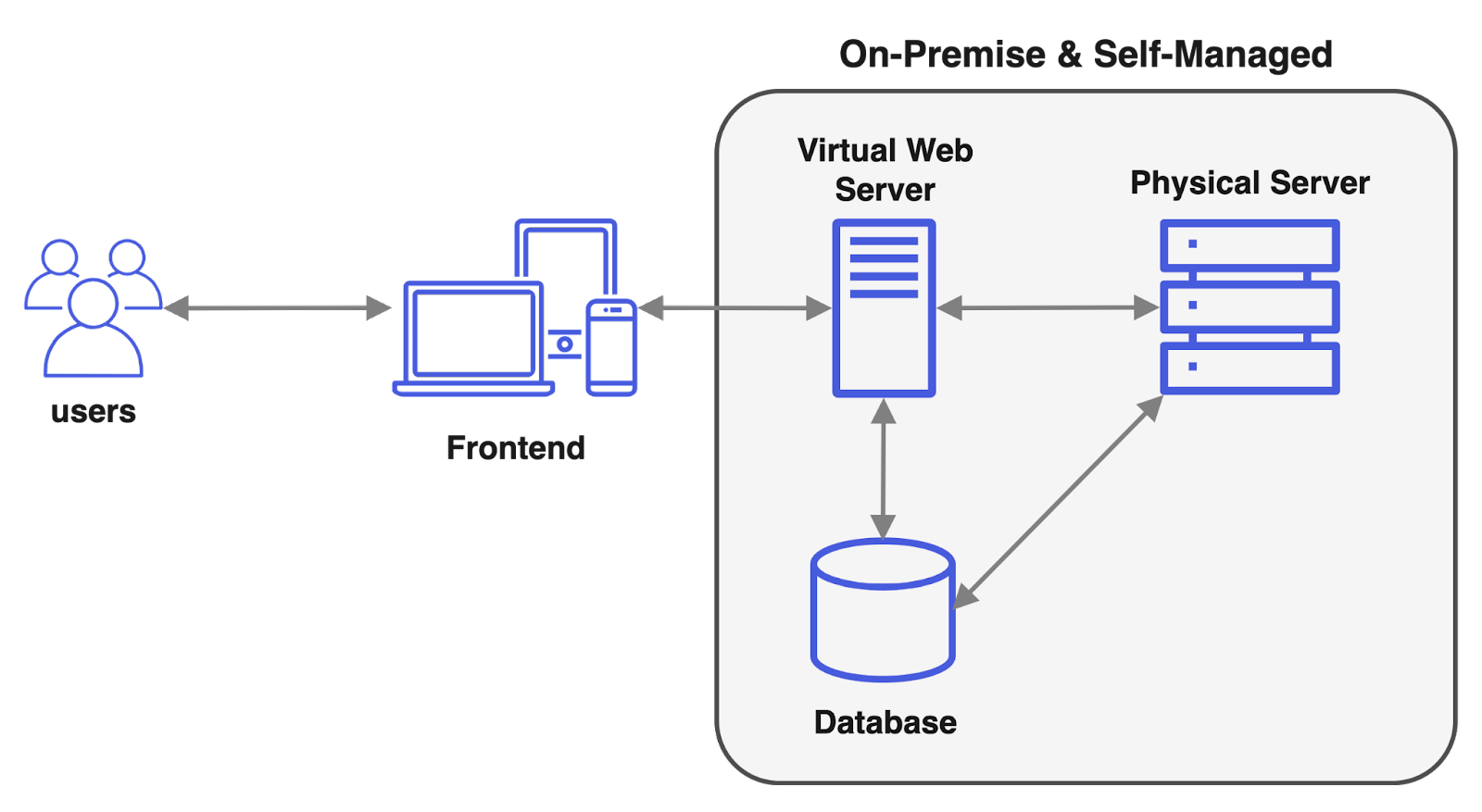
An alternative to “on-premise” is to choose an IaaS (Infrastructure-as-a-Service). For a monthly fee, an IaaS offers virtual servers, which may be shared among multiple customers on the same physical machine.
Adding a layer of abstraction on top of the underlying hardware means giving up a level of control, but also comes with the convenience of abstracting away hardware concerns such as server maintenance and scalability.
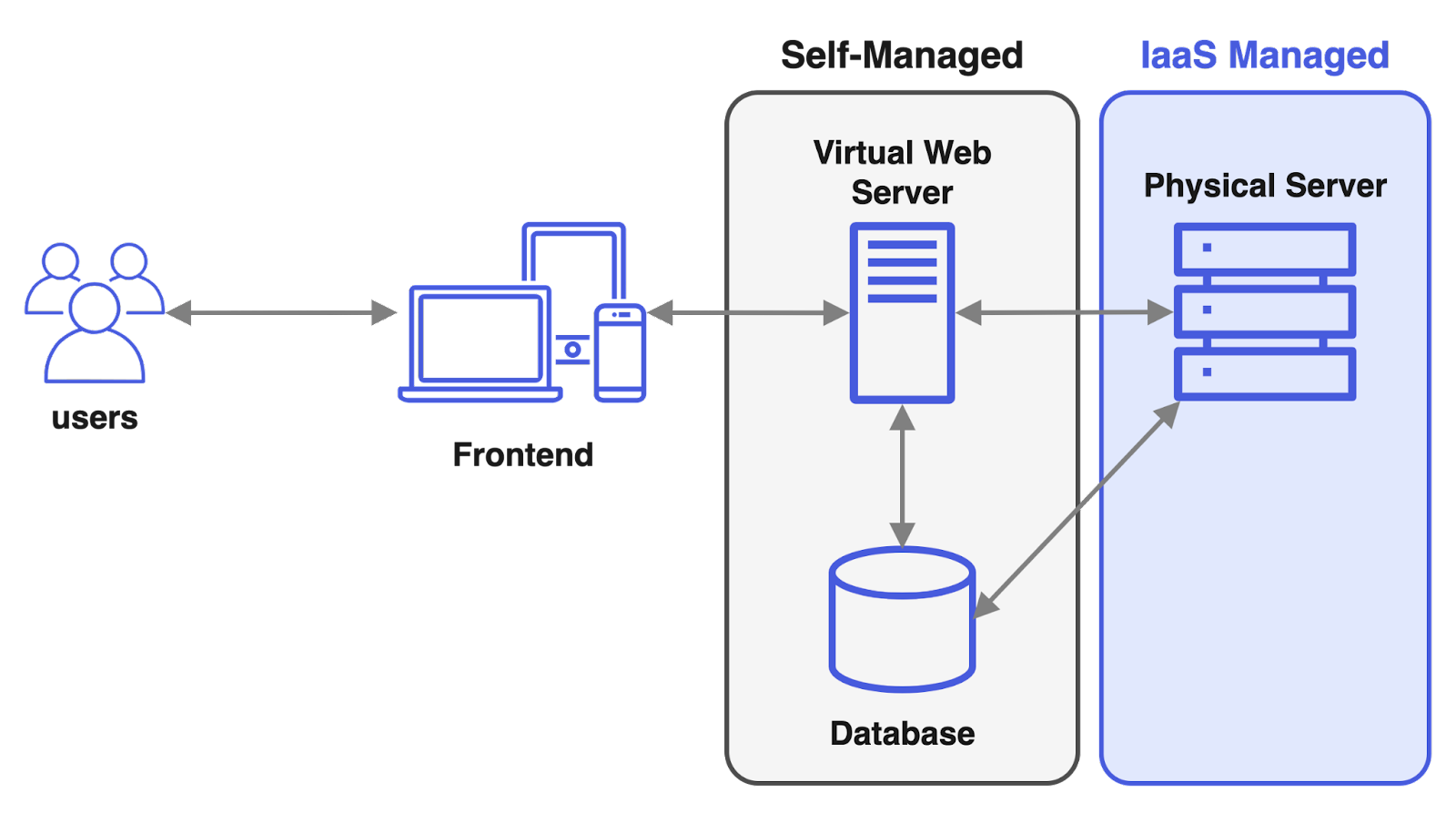
Note that this isn’t limited to a binary decision between one or the other. A hybrid solution consisting of both may be suitable.
2.3 Backend-as-a-Service (BaaS)
While IaaS abstracts away the physical storage and management of infrastructure, configuring the backend server remains challenging and time-consuming. As we hinted at earlier, a litany of configuration steps need to be completed. Firstly, the web server installation and configuration are necessary to handle incoming traffic, which may include serving static assets. To enable HTTPS, the web server must also be properly configured to obtain and manage TLS certificates. Registering the desired domain name with DNS involves yet more configuration. As the number of configuration concerns mounts, valuable time is diverted away from frontend development.
For developers who lack the expertise or desire to handle server-side infrastructure, Backend-as-a-Service (BaaS) services offer a valuable solution. BaaS allows developers to shift their focus towards frontend development while abstracting away the complexities of managing databases, web servers, application servers, virtual machines, and containers necessary to keep an application running.
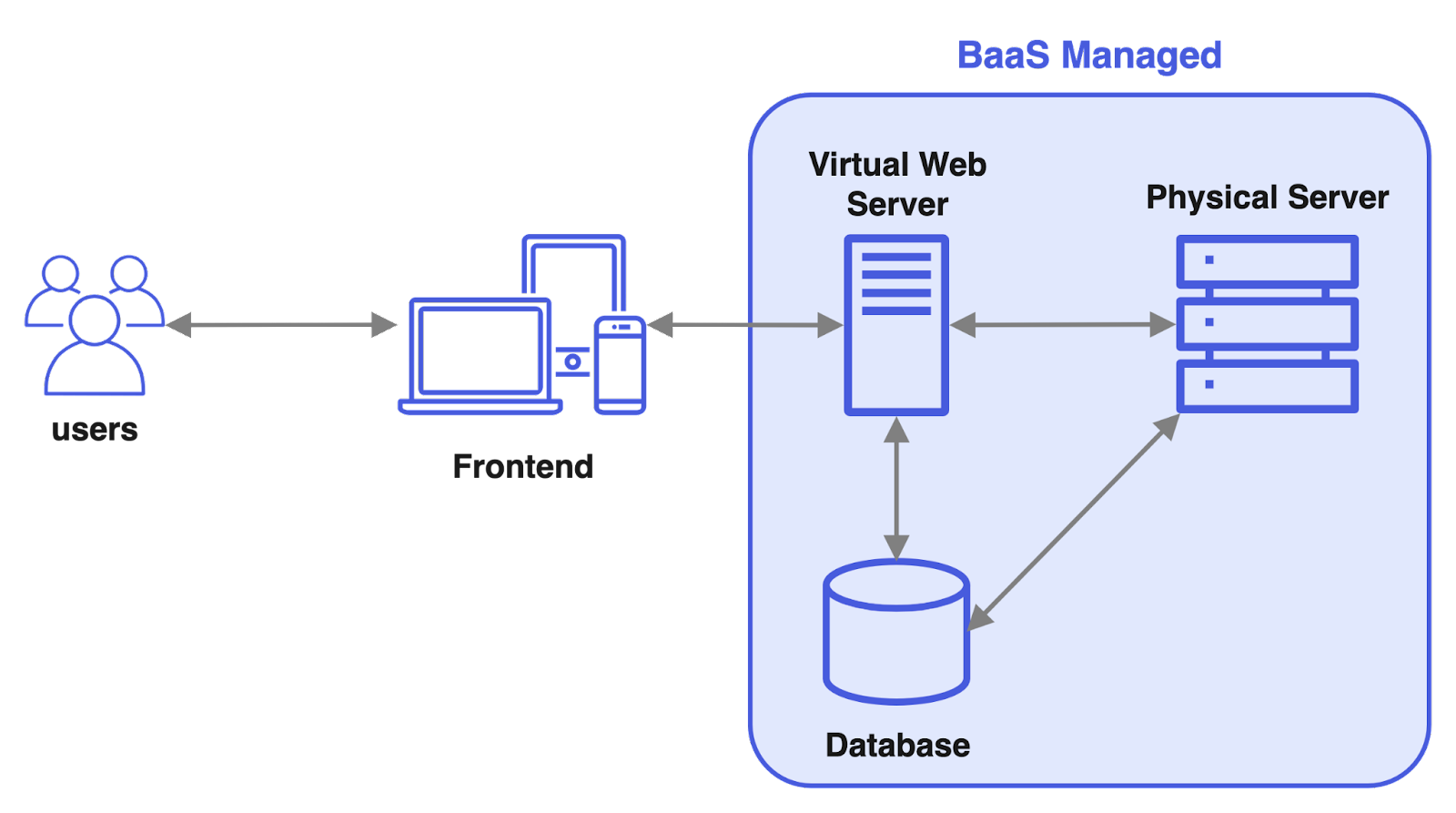
In RESTful web applications, which typically involve create, read, update, and delete (CRUD) operations at the frontend, there is an added advantage of using a BaaS: API endpoints responsible for handling these common CRUD operations can be automatically generated. This automation significantly simplifies the development process, as developers do not have to manually create these endpoints which reduces their workload. For these reasons, BaaS services are popular to get a frontend heavy application deployed quickly.
While Backend-as-a-Service (BaaS) does offer a higher level of abstraction, it comes with a trade-off: reduced control and flexibility over the backend infrastructure. For example, developers may want granular control over their BaaS components. They may want to set data retention policies or choose geographically where data is stored. These could be due to reasons such as regulatory compliance, for redundancy, or to minimize latency.
3 BaaS Solutions
If a developer deems BaaS appropriate for their application, an important consideration when deciding which service to choose is what type of database the application will use, and whether the BaaS supports it.
3.1 BaaS Database
Databases roughly fall within two categories: relational (SQL) and non-relational (NoSQL).
Relational databases share a common core – restrictive schemas and utilizing SQL for querying. With a relational database, the developer defines the structure of the data through the schema and by applying constraints to the table's columns. This enables a relational database to execute complex queries, such as joins across tables.
Conversely, NoSQL is a broad term that covers databases that are schemaless, which makes it easier to evolve the data model over time, have lower administrative overhead without a schema to manage, and flexibility to store data in different ways.
This may be attractive to an early-stage application where the data’s final structure is yet undetermined. However, using a NoSQL database may present challenges as the application evolves.
NoSQL’s Lack of Standardization
One challenge is that NoSQL databases have diverse approaches, particularly regarding schema handling. Take the topic of schema, for example:
- MongoDB (schema-less)
- ElasticSearch (dynamic schema)
- Cassandra (mimics a relational database)
Compare this to SQL databases which adhere to international standards. Standardization offers familiarity to developers – those already versed in SQL wouldn’t need to learn new query languages or database-specific syntax. When prototyping, BaaS users have one less concern to address.
NoSQL’s Lack of Purposeful Design
While a prototype can be developed quickly using a NoSQL BaaS, what are the eventual consequences of this design decision? One consequence of choosing a NoSQL database is the difficulty in modeling relationships between entities.
Data often exhibits relationships with other data. And if the application's data is highly relational, the absence or limited joining capability of a NoSQL database means that developers need to corral and relate the data in the frontend. As a result, the frontend is strained as more business logic is pushed to it.
In SQL databases, data is organized into tables where foreign keys establish the relationships between them. With this approach, combining data (JOINs) can be left to the database engine.
ACID
Lastly, the restrictive nature of relational databases allow them to uniformly be ACID compliant. At a high level, Atomicity, Consistency, Isolation, and Durability (ACID) are a set of properties that guarantee the reliability and correctness of database transactions in multi-user environments.
In contrast, NoSQL databases aren’t universally ACID compliant. Data inconsistency and data duplication can become an issue for a prototype using NoSQL as it matures, as the number of concurrent data operations grows.
Choosing SQL or NoSQL
As the popularity of cloud grows, there has been a corresponding shift towards NoSQL databases as web applications needed to scale. The flexibility and speed of NoSQL may make it the appropriate choice in those instances.
Similar to the earlier discussion on on-premise versus cloud hosting, the decision between SQL and NoSQL should be based on the specific needs of the application. When selecting a NoSQL database for short-term gains, one should consider the long-term implications that may arise once the application matures. In many cases, a relational database is considered as the default choice.
3.2 BaaS Migration
What happens when an application outgrows the BaaS it was initially built with? For instance, once the prototyping phase is complete and users begin using the application. If there is a substantial increase in application usage within a specific region, the BaaS user might seek to optimize performance for application users in that region. However, hosting options for that region may not be available within the BaaS service's offerings.
If a certain access pattern emerges as the application matures, the BaaS user may want to choose the underlying hardware that’s optimized for the application’s read/write patterns. For heavy read applications, SSDs may be favorable for faster reads. While disks may be favored for durability in write heavy applications.
If the BaaS service goes out of business, the BaaS user would have no choice but to migrate. Whether due to limitations of the service or the service shutting down, migrating from a BaaS to a custom solution can present challenges. A database backup can be done for both the data and the schema of a SQL database, making migrating the database straightforward.
3.3 Supabase
There are a variety of BaaS services for users to choose from. To provide some examples: companies such as AWS and Google offer BaaS solutions such as AWS Amplify and Google Firebase with proprietary NoSQL databases. For those looking for an open-source solution, Supabase offers a BaaS with a PostgreSQL database.
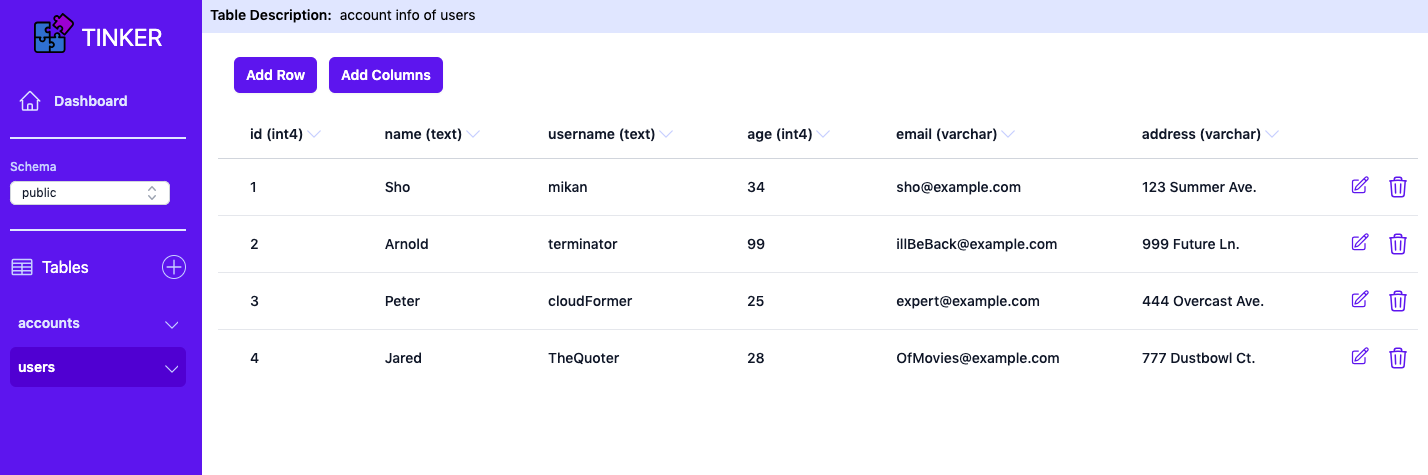
A unique aspect to Supabase is that it simplifies using a relational database through a user interface. During development, users often need to perform common database operations such as creating tables and adding rows. For instance, creating tables to store information about directors and films in a movie application.
As the application evolves, users may need to perform table modifications such as adding columns or constraints. In the context of the movie application, this could mean adding a new column for foreign keys to link genres in a separate table or enforcing a NOT NULL constraint to ensure film titles aren’t empty. Instead of executing these SQL commands through the command line, they can be performed entirely through the dashboard UI. This minimizes syntax errors that may occur when manually typing SQL commands. Furthermore, developers can quickly make modifications without looking up SQL syntax.
Supabase automates backend configuration and abstracts writing SQL queries, but also takes responsibility for hosting the user’s infrastructure. This lack of control may be a consideration for potential users, as free projects are paused after a period of inactivity. This also means that should the company shutter, the user would be forced to migrate and self-host.
As mentioned previously, there are instances where BaaS users may want to maintain more control. As mentioned previously, if they need hosting in a specific location. With supabase, only certain geographic regions are supported. Or if they need to choose the underlying hardware, which a managed service like supabase doesn’t offer. In specific cases, a self-hosted solution offers the convenience of handling installation and configuration, but is also malleable to adjustment. Supabase like other open source BaaS services can be self-hosted, which provides a level of abstraction over the backend but with greater control. To achieve this, users manually deploy the individual open-source components that make up Supabase on dedicated servers or in the cloud. While this approach avoids the installation and configuration of backends, it introduces the installation and configuration of the self-hosted BaaS.
4 Tinker
As we researched various Backend as a Service (BaaS) options, we were impressed with Supabase's user-friendly dashboard UI, which made data and schema modifications intuitive.
We sought to develop a framework that could mimic the user-friendly dashboard of Supabase that streamlined self-hosting on virtual private servers in the cloud. This led us to develop Tinker, an open source BaaS that deploys to a user’s AWS environment with minimal configuration.
Just like Supabase, each backend created with Tinker contains a relational PostgreSQL database. Once deployed, Tinker backends are accessible over the internet, enabling the user to start development on the application's frontend.
Compared to other BaaS solutions, Tinker offers a tightly scoped feature set. It is designed to accelerate prototyping for small applications, but its small feature set wouldn’t make it a good fit for enterprise level applications. Tinker backends can handle 1500 req/s while serving sub-second responses, but has no ability to scale to handle traffic beyond this threshold.

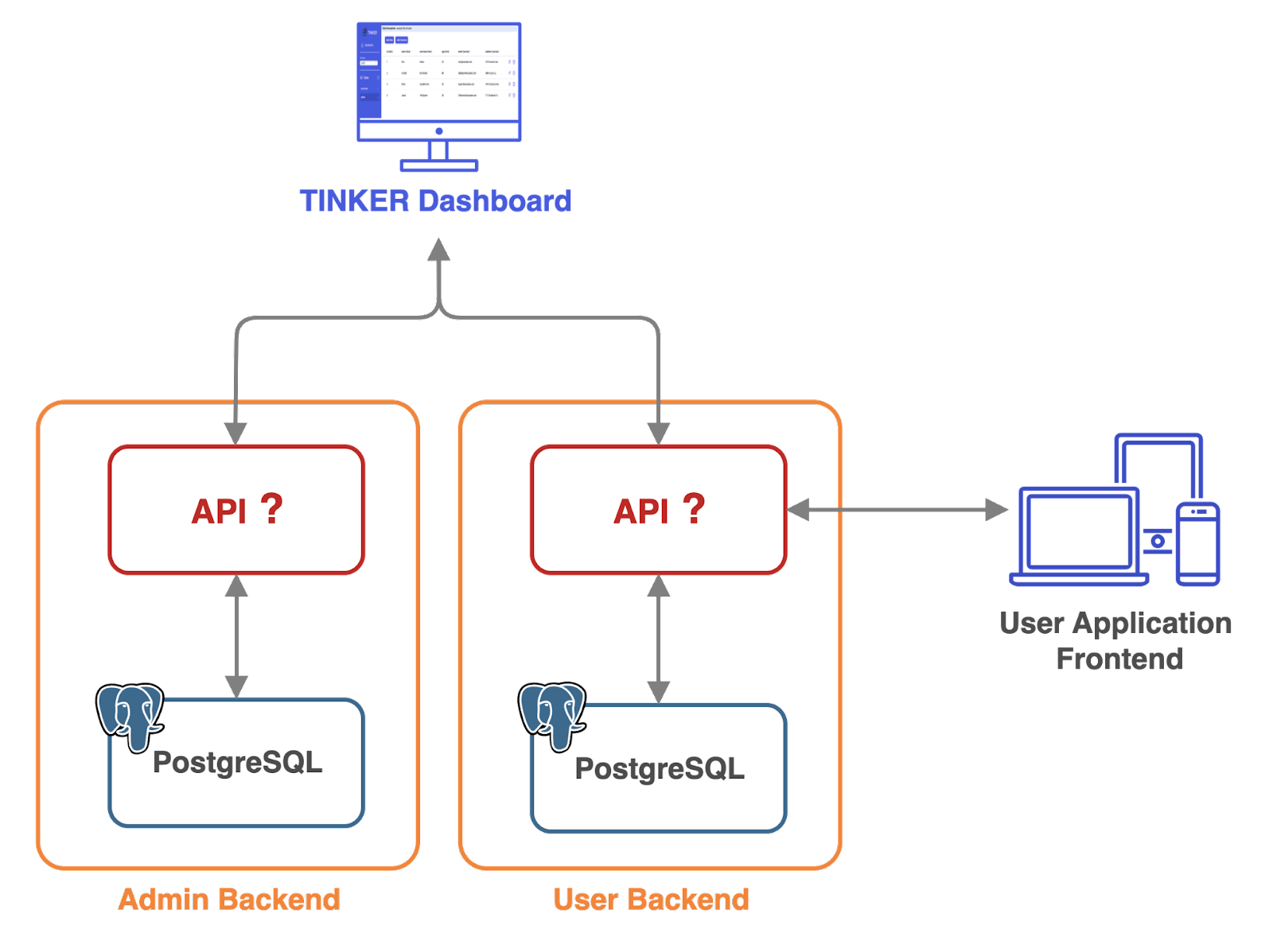
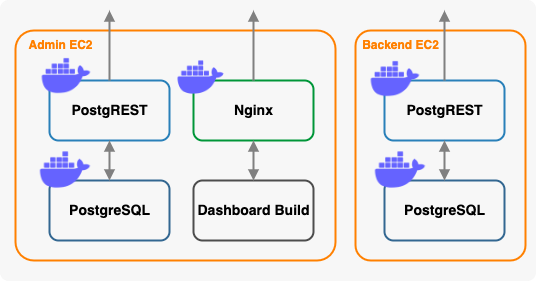
5 Architecture
Tinker consists of two user-facing components, a CLI and a dashboard UI. The CLI serves multiple functions, allowing users to deploy Tinker to their AWS environment, create and delete backends equipped with a PostgREST API and PostgreSQL database, and remove Tinker from AWS. On the other hand, the dashboard UI is a browser-based interface that empowers users to manage each backend’s database using a table editor.
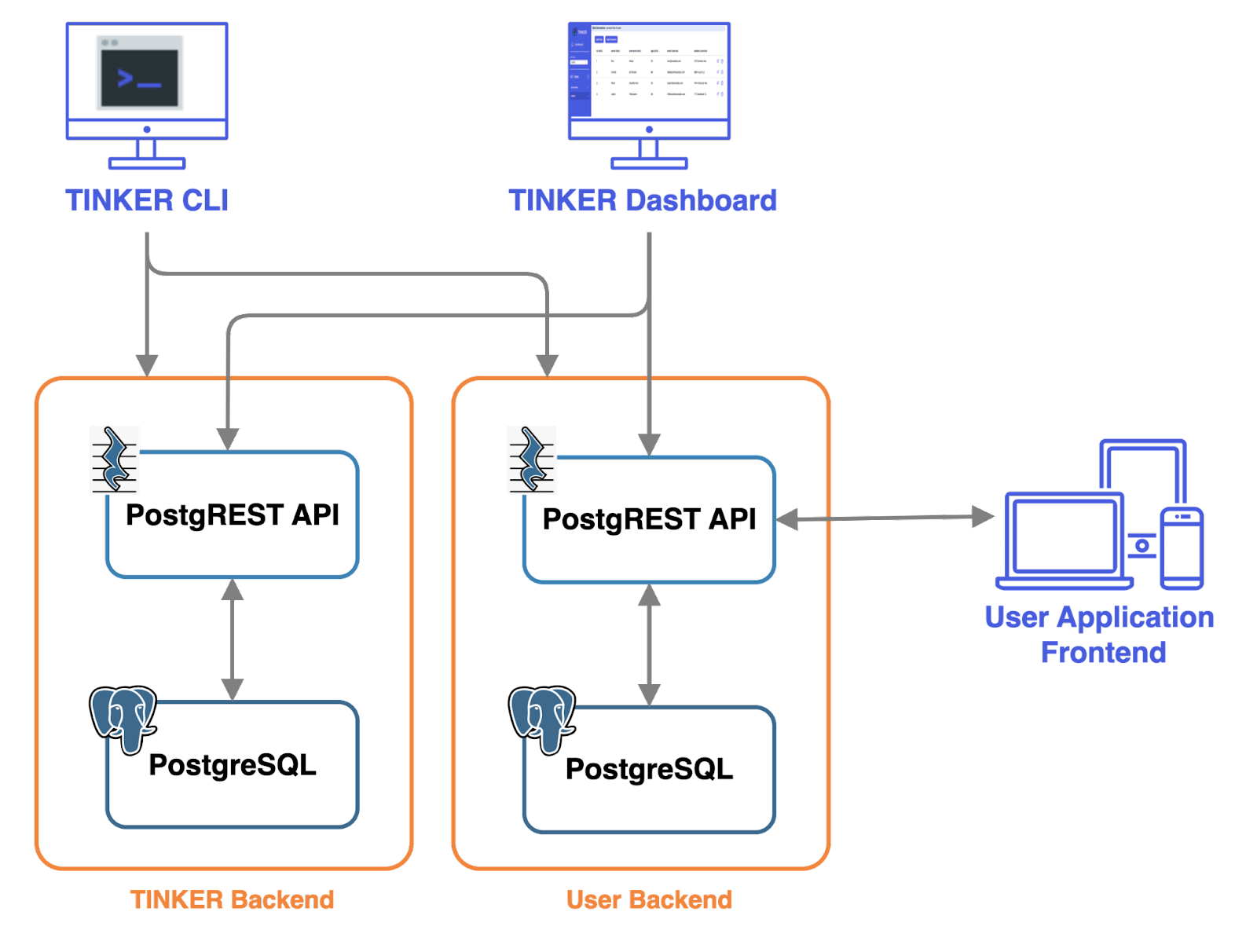
The table editor within the dashboard UI provides users with control over the schema and data stored within each PostgreSQL database. Users can perform tasks such as creating, editing, and deleting tables, as well as inserting, editing, and deleting rows.

The Tinker CLI takes a user’s domain name and uses AWS’s automation tool, CloudFormation, to set up and deploy Tinker’s infrastructure within a user’s AWS environment. CloudFormation handles the entire deployment process of Tinker’s dashboard UI and each user backend by creating infrastructure through customized templates.
5.1 Amazon Web Services (AWS) Infrastructure
Each user backend and Tinker’s admin backend are supported by EC2 compute instances which house all the needed components for an API server and database. With multiple EC2’s within Tinker’s Virtual Private Cloud (VPC), an Application Load Balancer (ALB) and Route 53 handles routing traffic to the appropriate EC2.
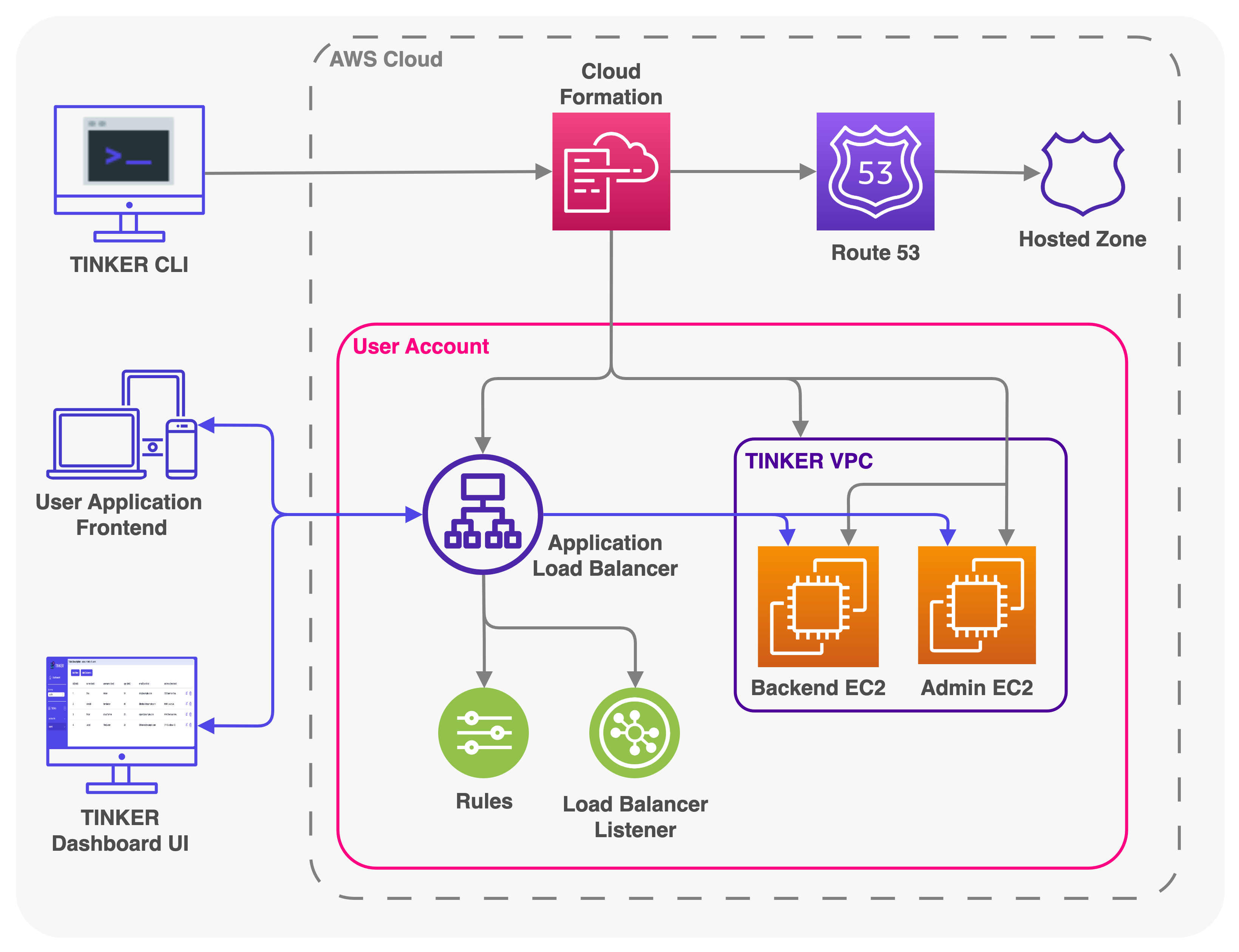
Within each AWS EC2 compute instance, Tinker employs an API called PostgREST to handle communication with the PostgreSQL database for both the Tinker dashboard UI and user frontend applications.
6 Engineering Challenges
6.1 Why PostgREST?
During Tinker’s development, we needed an API layer to handle communication to the PostgreSQL data layer. This included requests from both the dashboard UI and user’s frontend applications. A requirement for this API layer was that it needed to dynamically generate API endpoints unique to its respective database.
For example, in the case of the admin database, it manages a table of user backends. The dashboard UI needs to query an endpoint like admin.yourDomain.com/projects to display the list of backends. Similarly, if a user was creating the frontend of a movie application, the frontend might need to query an endpoint like cinemaCurate.yourDomain.com/movies to obtain a list of movies. These endpoints needed to be generated at the API layer.
For example, in the case of the admin database, it manages a table of user backends. The dashboard UI needs to query an endpoint like admin.yourDomain.com/projects to display the list of backends. Similarly, if a user was creating the frontend of a movie application, the frontend might need to query an endpoint like cinemaCurate.yourDomain.com/movies to obtain a list of movies. These endpoints needed to be generated at the API layer.
To fulfill this requirement, we chose to use PostgREST, an open-source web server that automatically generates a RESTful API from a PostgreSQL database schema. By inspecting the database, it creates HTTP endpoints that allow developers to interact with the database resources using standard HTTP methods and RESTful conventions. PostgREST also handles tasks like request routing, filtering, sorting, pagination, and access control.
Although PostgREST solved many of our API needs and became an integral part of Tinker, it lacked the same level of flexibility that a custom solution would have offered. In subsequent sections, we will explore the challenges that arose from this decision.
The Route Not Taken
We considered building the API layer with an app server like Express, writing logic to dynamically create CRUD routes, and then pairing it with a web server like NGINX. However, it made more sense to adopt an existing open-source solution, rather than writing this logic from scratch.
6.2 Remote Procedure Calls (RPC)
When building the dashboard UI, PostgREST’s automatically generated endpoints proved effective for handling requests involving Data Manipulation Language (DML) operations such as inserting, editing and deleting rows (data). However, PostgREST had a few limitations when using it for developing Tinker’s dashboard UI table editor. First, it did not have endpoints for Data Definition Language (DDL) operations such as creating, editing, and deleting tables, which was crucial for making a table editor. Second, it did not allow custom API endpoints which could have circumvented the first problem.
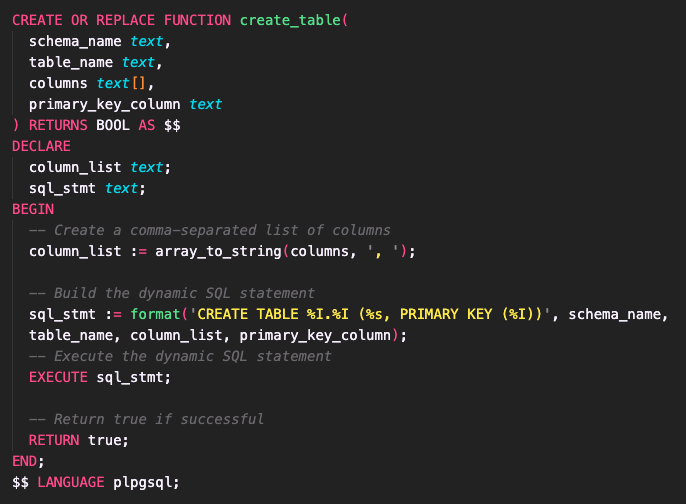
To address these limitations, we turned to PostgreSQL’s stored procedures and PostgREST’s /rpc endpoint, which exposes those stored procedures. Stored procedures are functions within a relational database that can store and execute both DDL or DML SQL statements. With the help of the /rpc endpoint, we were able to execute stored custom PostgreSQL procedures necessary for creating a table editor.

6.3 No outbound HTTP calls with PostgREST
As covered in the architecture section, Tinker is composed of two parts: The Tinker CLI and the dashboard UI. Initially, we envisioned the Tinker CLI only handling the deployment and teardown of Tinker’s admin infrastructure. While management of user backends and database interactions would be handled through the dashboard UI. However, because the PostgREST API is primarily a wrapper around the PostgreSQL database, it lacked the customization capabilities of a full-fledged application server. This meant we couldn’t create a custom endpoint that could send HTTP requests to CloudFormation, in order to provision or delete resources using the dashboard UI.
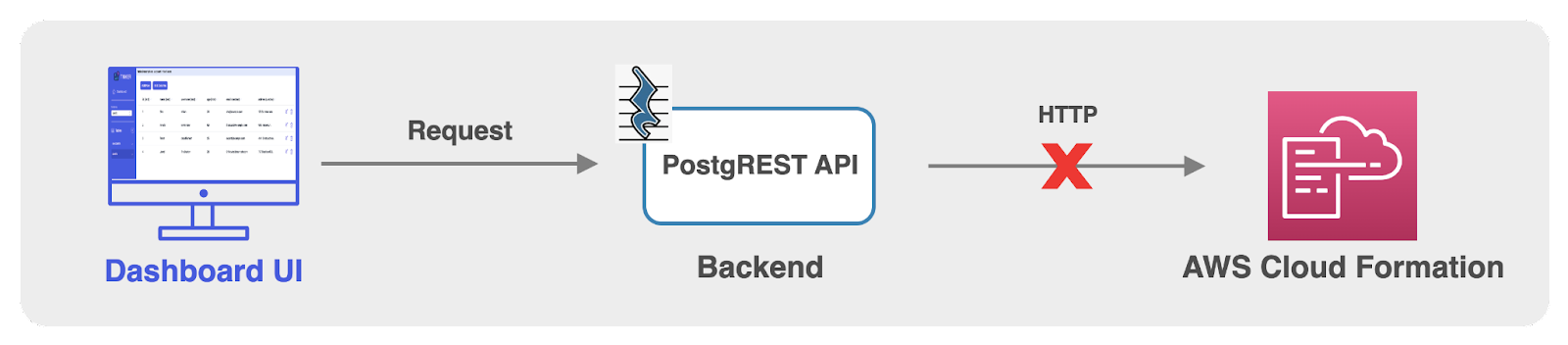
With this limitation, we needed to amend our approach for creating and deleting user backends.
Expanded CLI
We decided to expand the capabilities of the Tinker CLI beyond our initial vision, in order to tackle PostgREST’s limitations. To initiate the deployment of Tinker, users begin by installing the Tinker CLI package via npm. Subsequently, they store their AWS credentials on their local machine using the AWS CLI. Tinker’s CLI deploy command then provisions infrastructure to their AWS account using the AWS Software Development Kit (SDK) and leveraging the AWS credentials located at ~/.aws/config on the user’s machine. The AWS SDK utilizes these credentials when the Tinker CLI makes calls to CloudFormation; thus Tinker never handles user credentials directly.
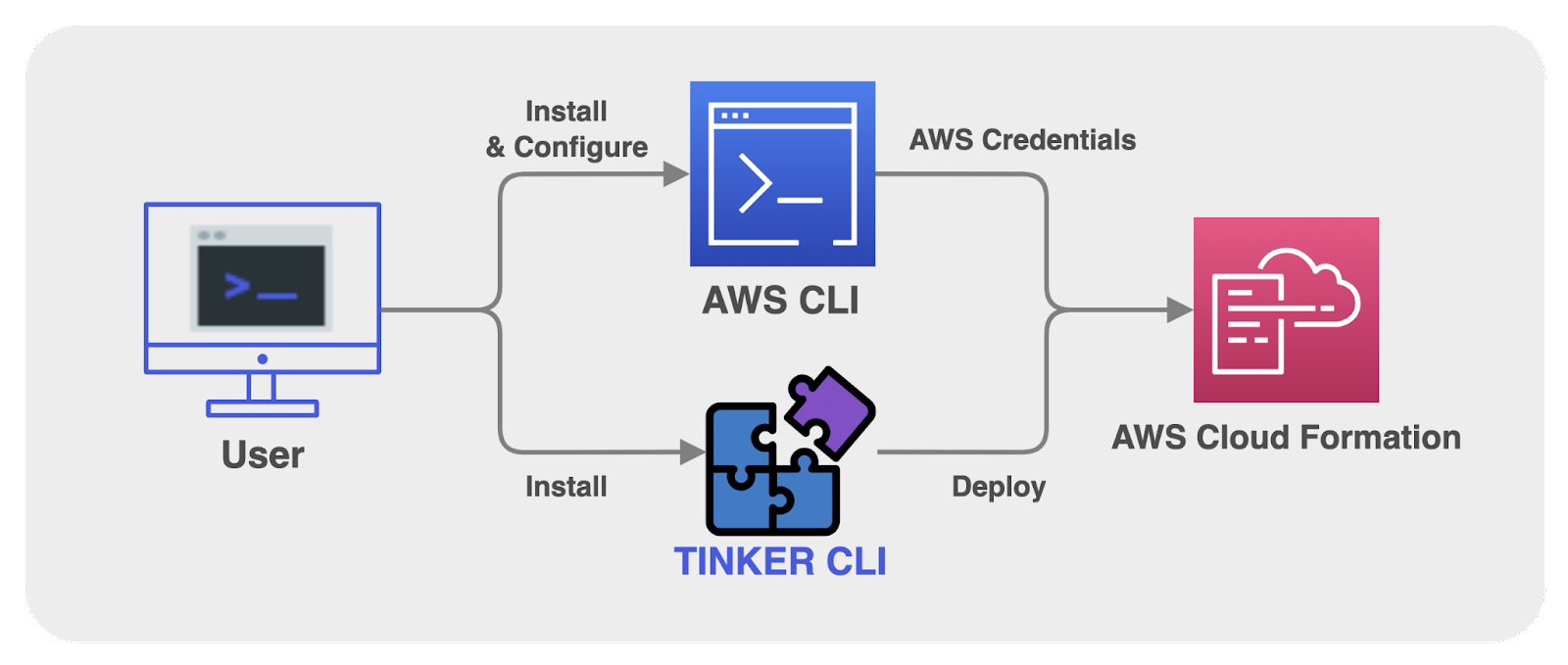
As a result of extending the functionality of the Tinker CLI, the dashboard UI’s sole focus would now be data manipulation and definition. On the other hand, the Tinker CLI would now handle all user backend management on top of the initial deployment and teardown of the admin infrastructure.

The benefits of this strategy were two-fold. First, we create a clear separation between the responsibilities of the dashboard UI and the Tinker CLI. Second, we refrain from handling user credentials throughout Tinker. By clearly separating the responsibilities of the CLI and the dashboard UI we were able to consolidate all AWS provisioning related code and CloudFormation templates into the CLI, and keep the frontend dashboard free of any resource provisioning logic.
By moving all user backend provisioning to the CLI, we avoided potential security concerns with embedding a user's AWS credentials within Tinker. We took the security of a user’s AWS credentials seriously and wanted to avoid handling them within any part of Tinker. The alternatives we considered included storing a user's credentials within the Tinker admin database or embedding them into the frontend through environment variables. However, this approach would have made the credentials vulnerable to exploitation and interception as they traversed networks, unlike when stored solely on the user's local machine
Despite the added benefits of expanding the CLI functionality, there was a tradeoff to consider. The dashboard would no longer be able to manage user backend provisioning, and would now be strictly limited to data manipulation and definition; this made the dashboard UI less intuitive as users would now be required to create and delete backends through their terminal.

Possible Solutions
As mentioned in the previous section, we explored using the AWS SDK within the dashboard UI to provision resources for user backends. This approach would have required us to interact directly with the user’s AWS credentials, which could pose potential security risks. We wanted to avoid handling a user’s sensitive information due to these concerns.
Another alternative we explored was using AWS Lambdas, which are serverless functions executed in response to specific triggers. A Lambda function could have been employed to handle CloudFormation calls and be triggered from the frontend dashboard UI. However, this approach also required handling the user’s AWS credentials. While we could provision the AWS Lambda during the initial Tinker deployment without directly touching the credentials, invoking the Lambda function in the frontend still necessitated the use of AWS credentials.
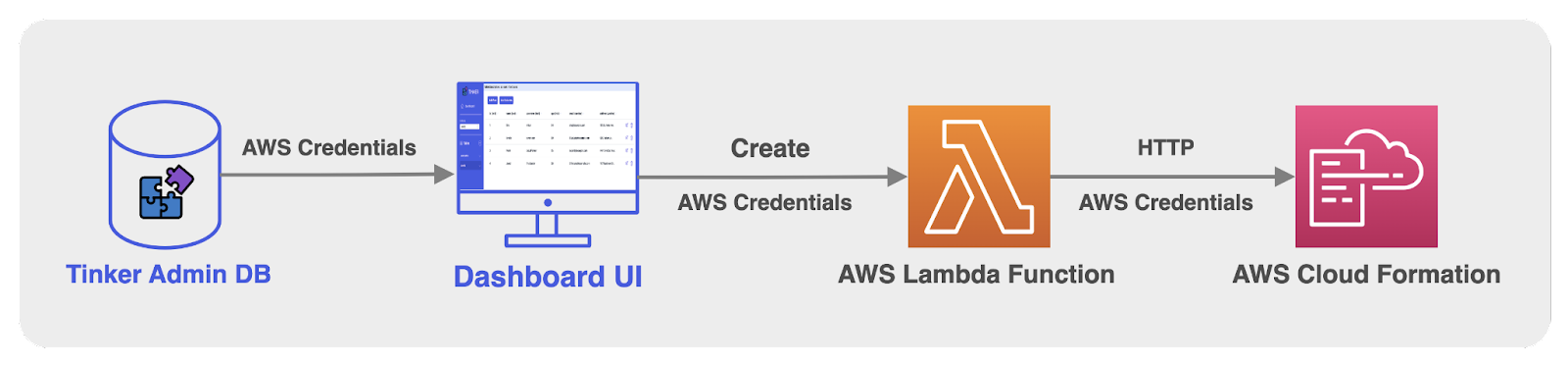
6.4 Database Security
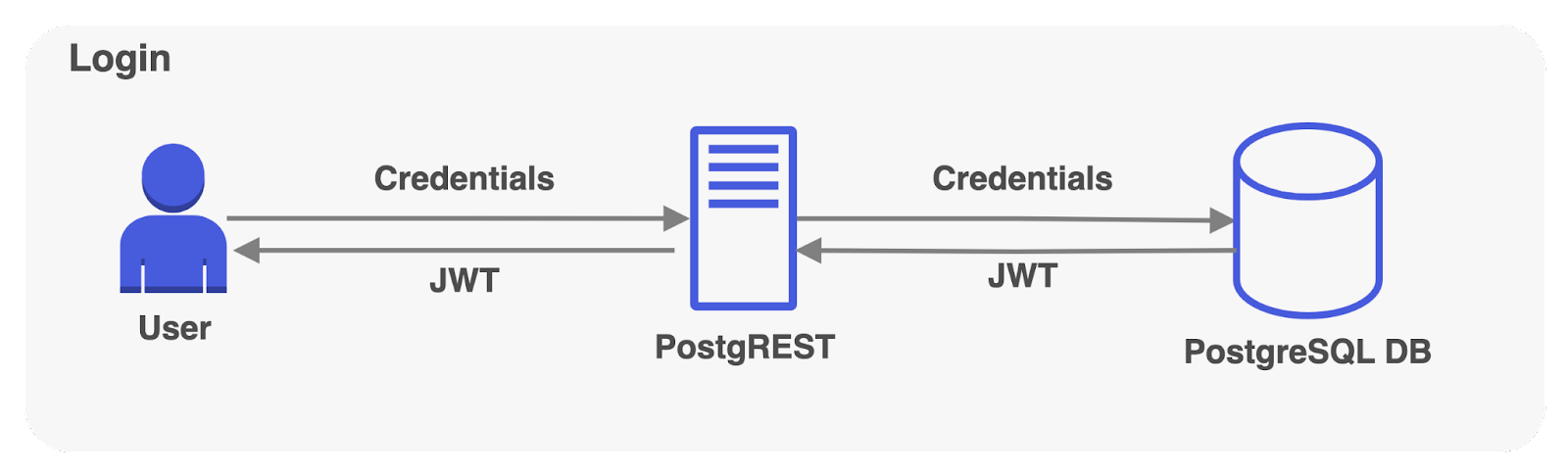
The use of a public-facing PostgreSQL database with the PostgREST API raised security concerns due to PostgreSQL and PostgREST's lack of default security measures. To overcome this security concern we leveraged PostgREST’s ability to accept JSON Web Tokens (JWT) as a means of authentication and roles, PostgreSQL’s built in authorization mechanism.
Roles
PostgreSQL utilizes roles as the mechanism for managing privileges. They allow administrators to define sets of permissions that can be assigned to roles. By doing so, the permissions control what actions a role can perform within the database, such as reading, writing, modifying, or executing functions.
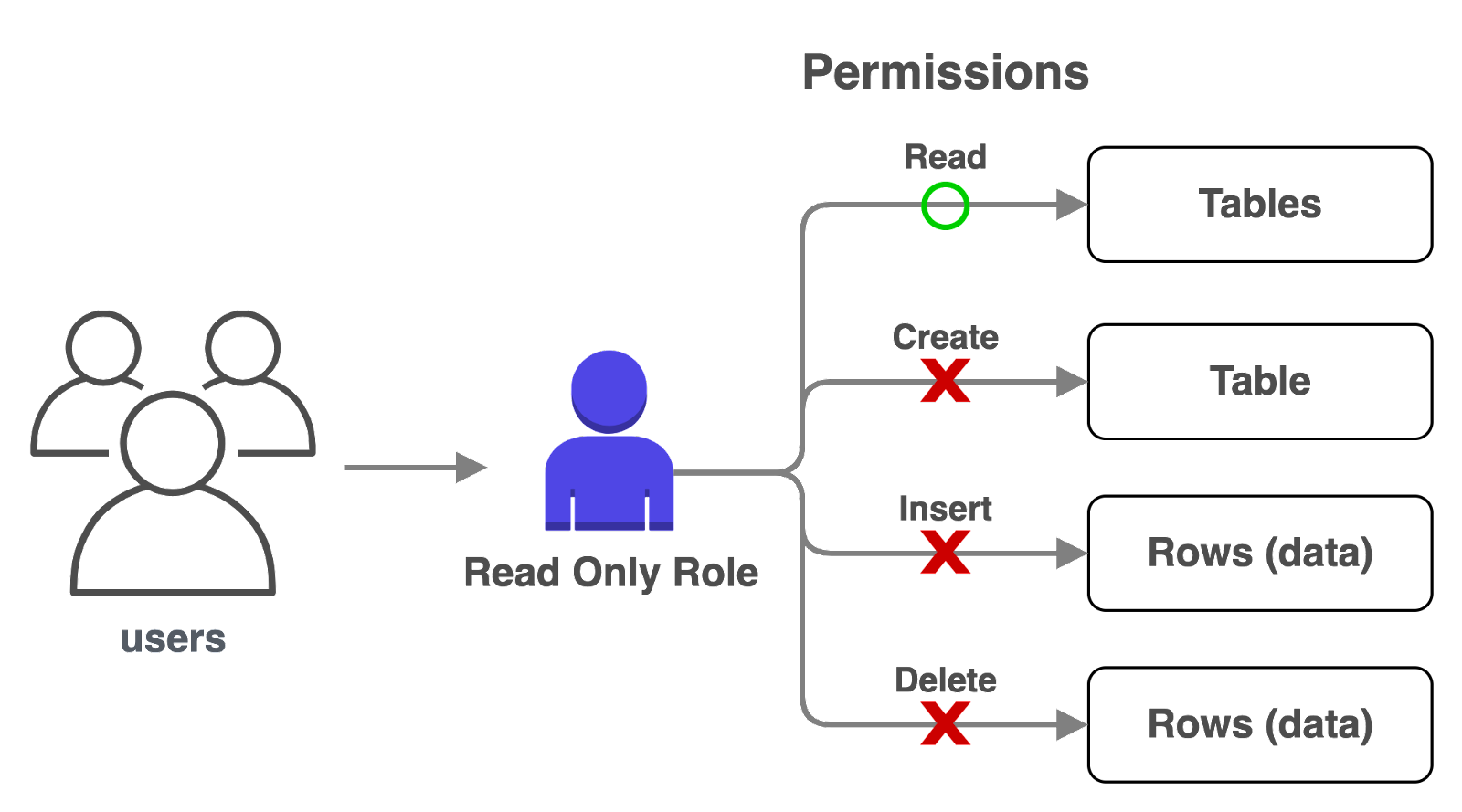
We configured Tinker such that when a request arrives with the correct credentials, PostgREST establishes a connection to PostgreSQL and assumes the “admin” role with superuser privileges. Superusers have the highest level of authority in PostgreSQL and can perform any action without restriction.
JSON Web Token (JWT)
The JWT is used to transmit secure information as a JSON object for authentication. They consist of three parts separated by periods: a header, a payload, and a signature. The header contains information about the token's type and the cryptographic algorithm used for its signature. The payload contains claims, which are statements about the user. The signature is created by encoding the header, payload, and a secret key with a specific cryptographic algorithm. The signature ensures that the token is not tampered with and can be verified by the server to establish the token's authenticity

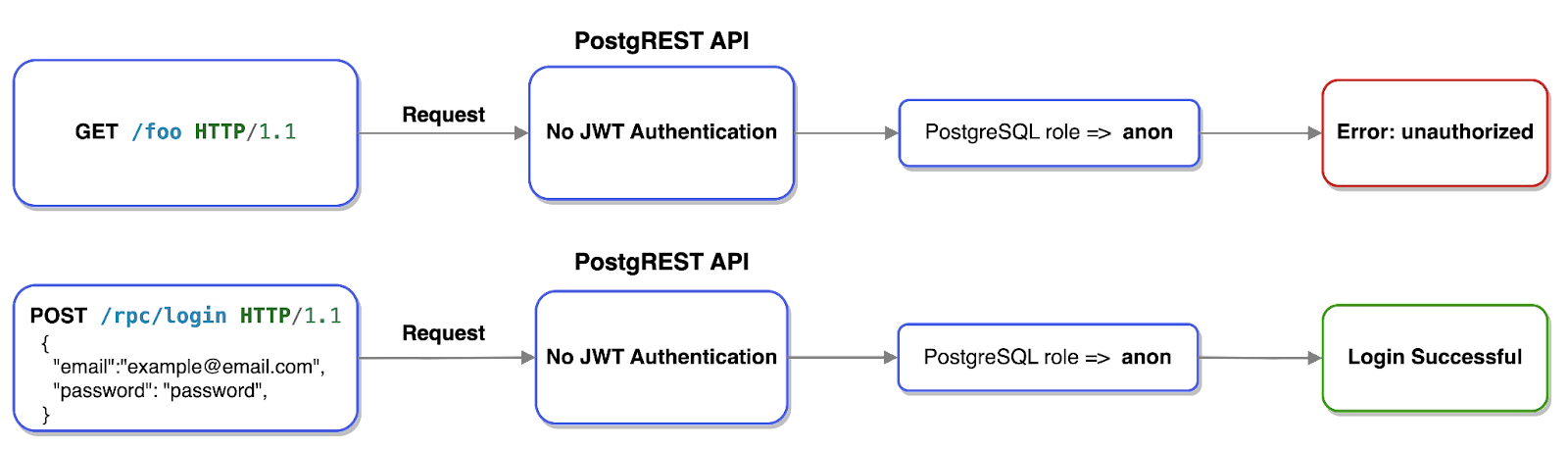
When a request with a JWT is made to PostgREST, it decodes the JWT using a stored predefined secret and assumes the claimed PostgreSQL role, defined in the payload. For example, when a user accesses the list of user backends from the dashboard UI, a request is made to PostgREST with a JWT containing the admin role.
If the claimed role in the JWT does not exist in PostgreSQL or if the secret used to encrypt the JWT does not match the stored secret within PostgREST, the authentication process fails and the request is rejected.
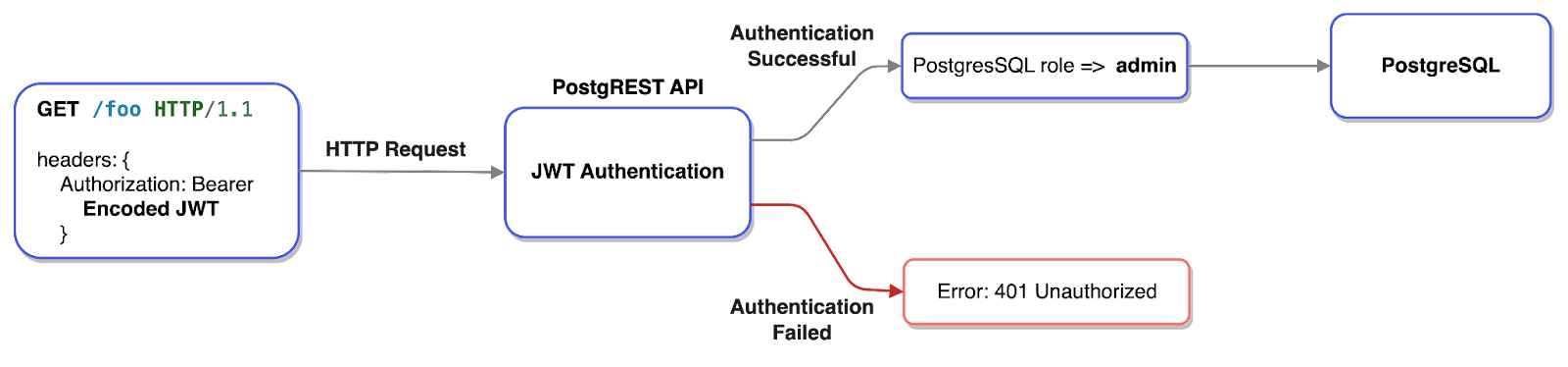
When connecting to PostgREST without a JWT, PostgREST will connect the user to PostgreSQL’s anonymous role which has predefined limited privileges. In Tinker’s case the anonymous role is only privileged to handle user logins.
6.5 HTTPS
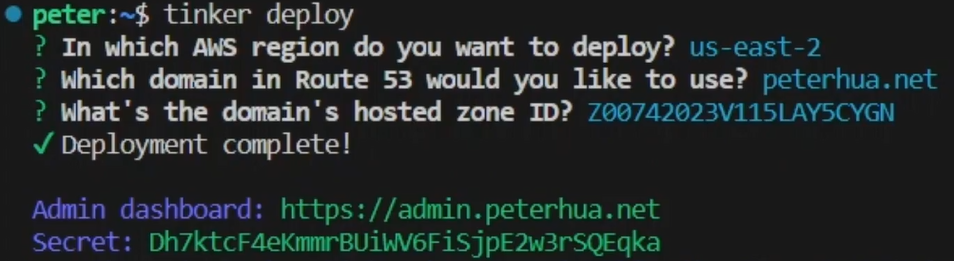
As part of the initial Tinker deployment, a randomly generated JWT secret is created. PostgREST servers are configured to use this secret to decode JWTs from incoming requests. Additionally, the secret is displayed as an output for the user.
Signup Flow
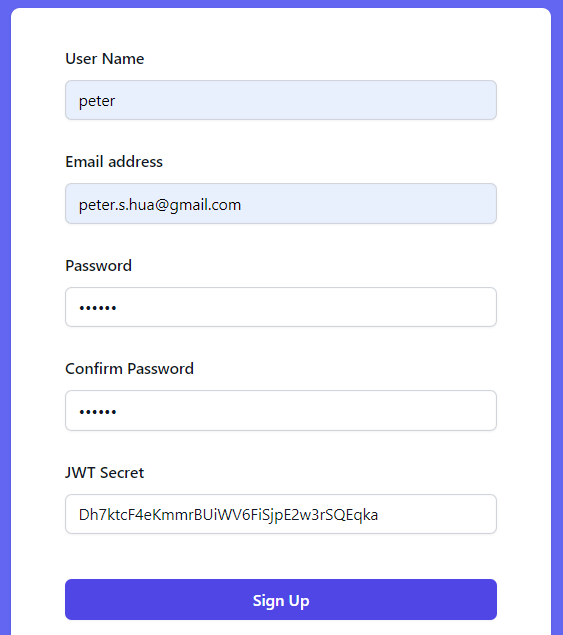
Users include this secret in the signup form when creating a new account. When submitting the signup form, the frontend generates a JWT using the provided secret and includes it in the signup request to the backend. Upon receiving the signup request, PostgREST decodes the JWT, enabling the storage of the new user's credentials in the admin database.
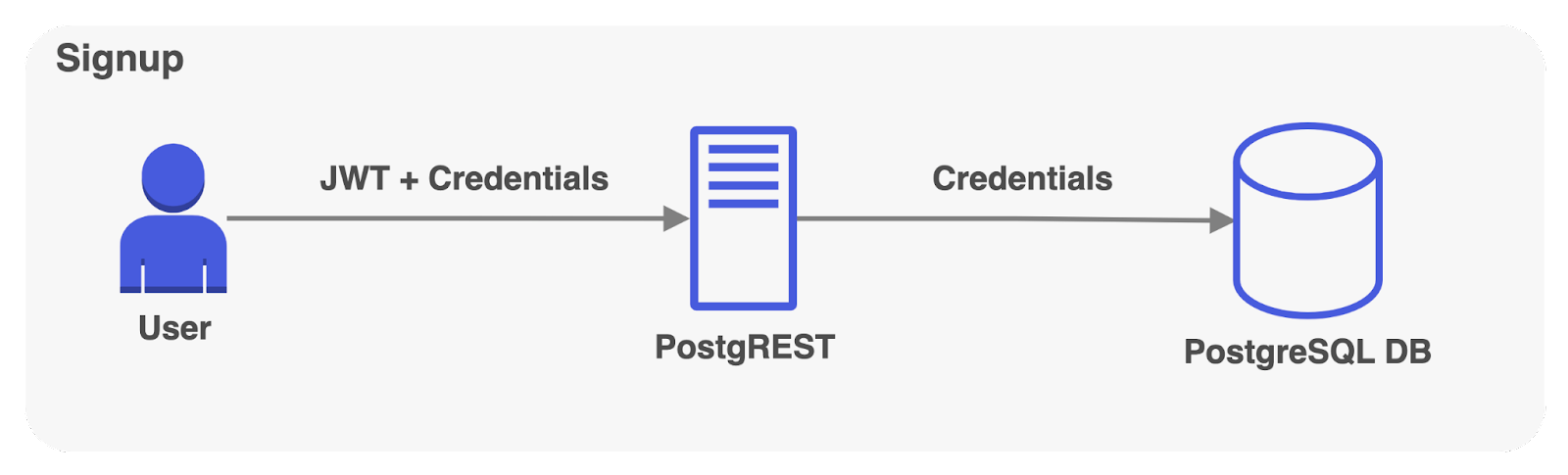
Now, users can sign in from different clients without needing the secret. Whenever a user signs in, PostgREST verifies the provided credentials with the stored credentials in the admin database. Upon successful login, PostgreSQL mints a JWT containing the “admin” role. Future requests to PostgREST include this JWT, which authenticates them as admin users, and authorizes them to interact with PostgreSQL databases.
6.6 JWT Security
An issue we identified with the signup flow design is that PostgREST
does not implement HTTPS. That meant that within each request, the
JWT and user credentials were exposed to potentially malicious
actors. JWT’s are encoded, not encrypted; the JSON data can be seen
by anyone intercepting the requests. A malicious actor could inspect
the sign-in information and JWT, then begin sending data-altering
requests to PostgREST. This meant that a component was needed
upstream of PostgREST to handle HTTPS traffic.
To guard Tinker infrastructure and protect Tinker users, the
dashboard UI makes HTTPS requests to the admin backend. Furthermore,
we chose to use an Application Load Balancer (ALB) that’s
responsible for handling all HTTPS requests to Tinker components,
and routing HTTP downstream.
Centralizing the TLS Certificate
To establish an HTTPS connection, a TLS handshake first takes place. During this process, the server sends its TLS certificate to the client. The client then verifies the authenticity of the certificate using the certificate provider's validation.
Given that Tinker's infrastructure is built on AWS, we sought a product that could handle the TLS certificate while seamlessly integrating with the AWS ecosystem. Utilizing an AWS product like the Application Load Balancer (ALB) proved to be a straightforward approach when paired with AWS Certificate Manager.
Rather than create a certificate for each user backend when spun up, we decided to centralize certificate management, which is known as TLS offloading. This approach offloads the responsibility of decrypting and encrypting TLS traffic from downstream servers. As a result, the admin and user backend servers are relieved of the burden of handling TLS certificates and HTTPS processing.
To achieve this, DNS records are created for the admin server and user backend servers. For example, record names like admin.yourdomain.com and todos.yourdomain.com are set to point to the ALB's address. A single certificate with a wildcard is created to cover all subdomains, *.yourdomain.com.
Unlike traditional setups, each user backend doesn't need a dedicated server like NGINX to handle certificates and process HTTPS requests. Instead, the ALB takes on this role, which simplifies the backend infrastructure.
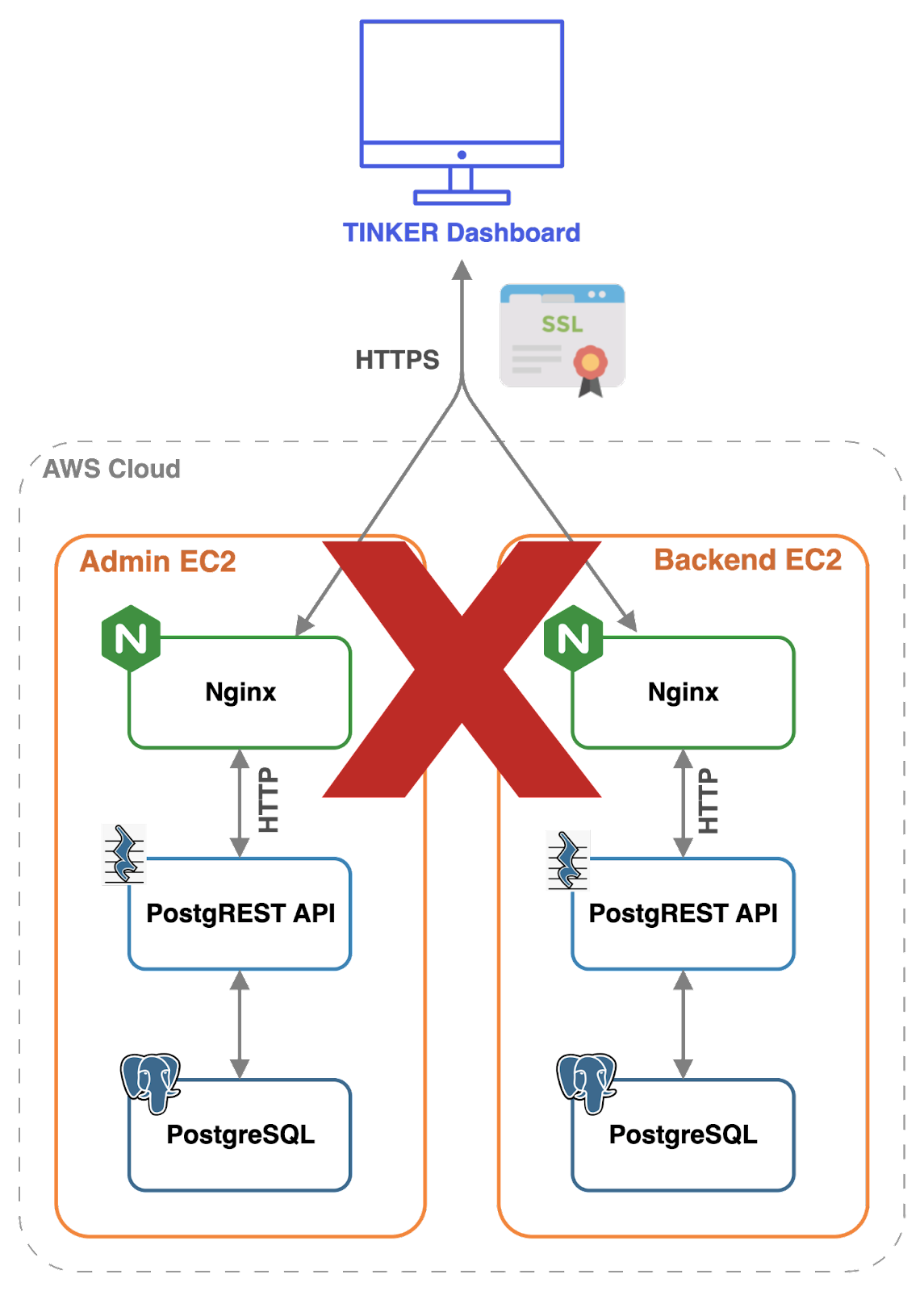
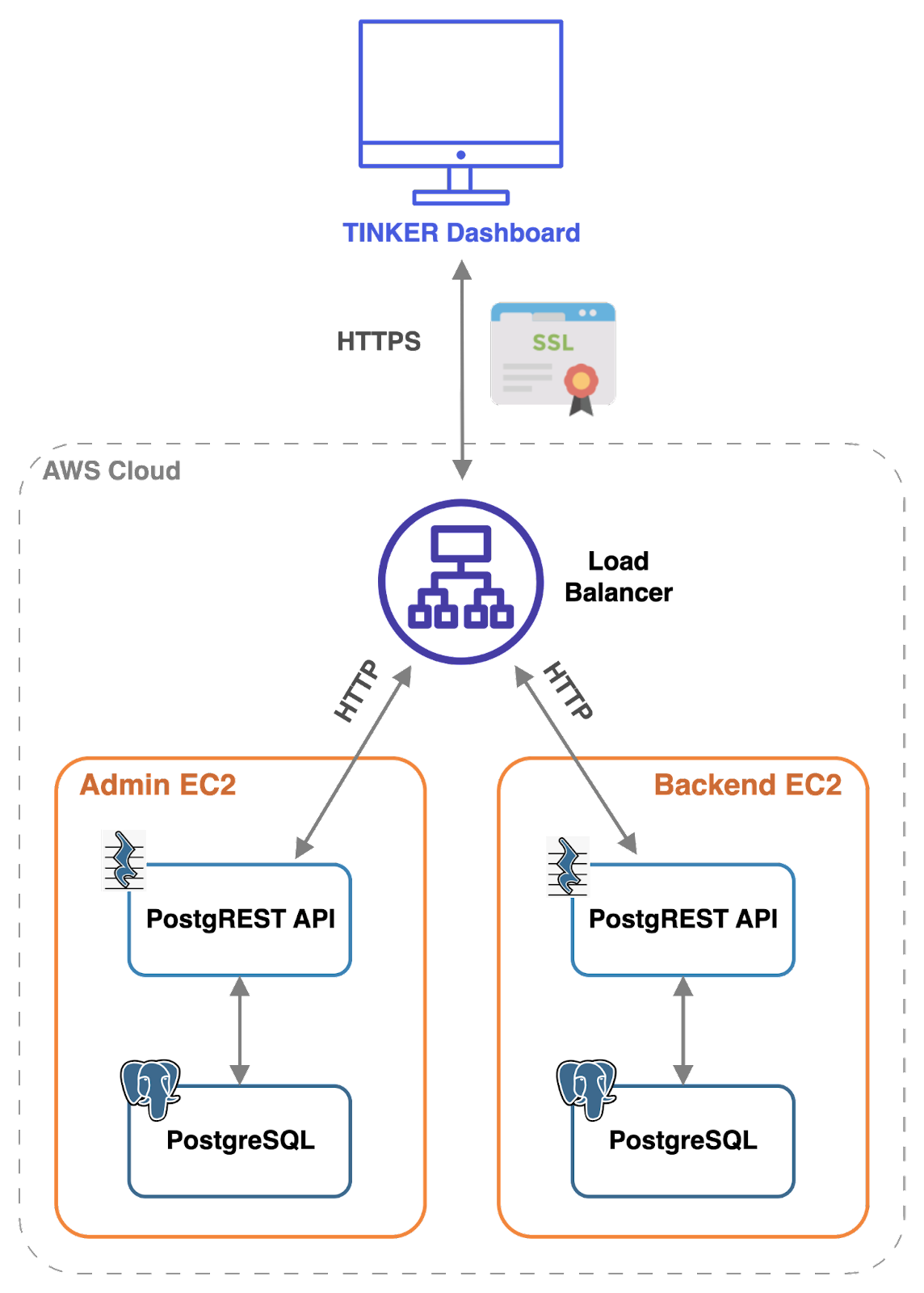
However, this approach pushes complexity into the ALB configuration, which must be appropriately set up to route traffic. Upon receiving incoming requests, the ALB inspects the request header's "Host" field to identify the destination domain. Using this, the ALB routes the traffic to the appropriate server, whether it's the admin backend or a specific user backend.
While Tinker aims to mitigate configuration challenges for users, it's important to note that the requirement for users to purchase a domain name for the TLS certificate does introduce an additional overhead.
6.7 Self Hosting
Though BaaS offers a user rapid development, reduced configuration, and infrastructure overhead, there is a looming possibility that the BaaS chosen will end their services, requiring a user to migrate their application data and resources. We also wanted Tinker to provide a BaaS that gives users control over their backend components. This is why we chose Tinker’s infrastructure to be self-hosted on a user’s AWS environment. Though this choice added significant complexity to Tinker’s automatic deployment processes, self-hosting Tinker allowed a user to have full control of their infrastructure and data, to alter any component of Tinker to fit their needs.
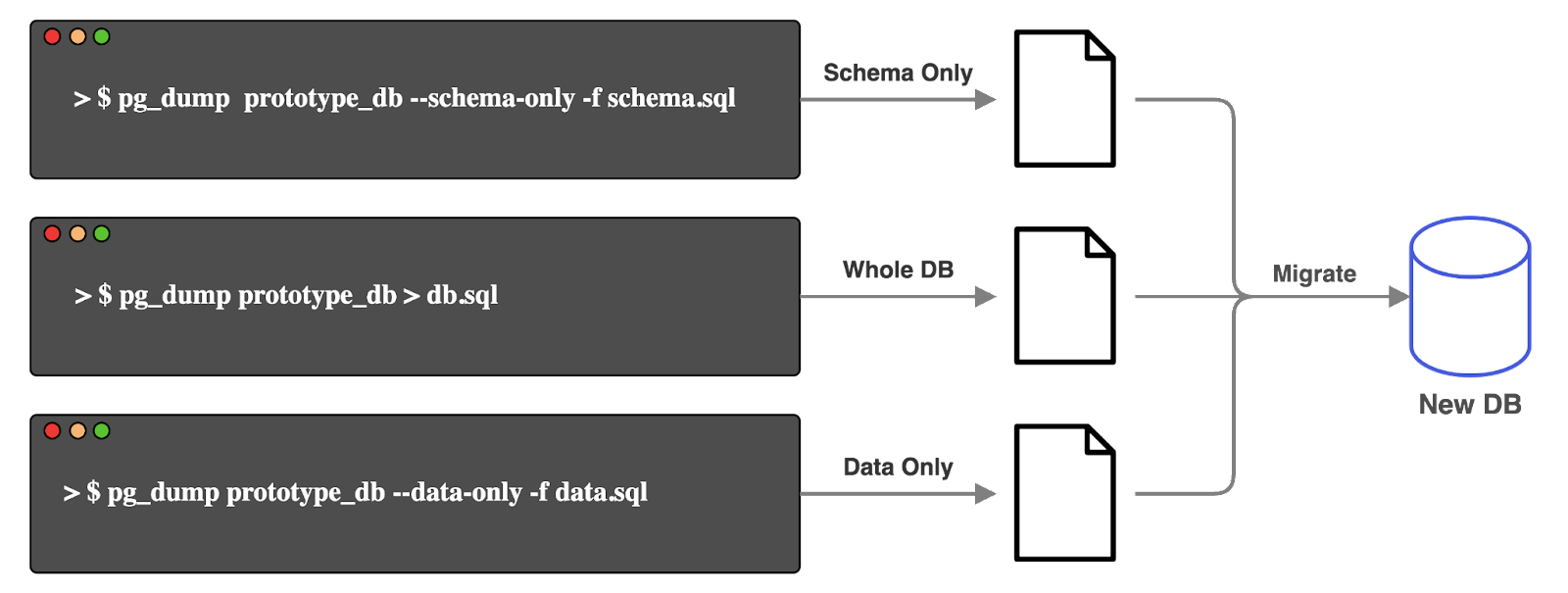
Because Tinker uses PostgreSQL, users can utilize its pg_dump command to backup all data and database schema into a file. PostgreSQL’s pg_dump command can be customized to backup only data or only schema. These files can then be used to recreate the user’s database during migration in a new environment.
6.8 Automated Deployment
During the initial deployment of the admin backend, and for user backend deployments, PostgREST and PostgreSQL must be installed and configured within each EC2 instance. This is done using CloudFormation templates, which not only define the AWS resources that get deployed, but also the configuration of them. In the case of EC2 instances, the templates include the Linux commands to install, configure, and run NGINX, PostgREST, and PostgreSQL. The problem that we ran into through this approach was that the CloudFormation templates included a long list of Linux commands that were difficult to understand. As the template grew, its maintenance became increasingly cumbersome.
Docker
To streamline the deployment process, we utilized Docker. Docker can package applications and their dependencies into isolated containers. These containers can be deployed and run consistently across any underlying Linux-based host. In short, it simplifies the process of installing and configuring applications.
During the initial Tinker deployment and the creation of user backends on EC2 instances, we leverage Docker to pull PostgreSQL and PostgREST images and configure them accordingly. Subsequently, these images are executed as containers.
Docker Compose
Since Docker containers are isolated and PostgREST needs to communicate with PostgreSQL, we used Docker compose to create a network that connects them. Within a Docker compose template, services are defined for NGINX, PostgREST, and PostgreSQL.
This implementation involves the installation of Docker and Docker Compose during each EC2 instance's launch. Docker Compose then retrieves images specified in the compose template and handles the orchestration of NGINX, PostgREST, and PostgreSQL
By adopting Docker, we simplified our CloudFormation templates. Rather than cluttering the templates with numerous installation and configuration commands, Docker containers encapsulate all these steps. This extracted the logic associated with individual components within an EC2 instance from the CloudFormation template, and placed it in an organized location – the Docker compose template.
Docker added an additional layer of complexity, which impacted both our development of Tinker and its users. Users seeking to fine-tune their PostgreSQL configuration now have to understand Docker and Docker compose, and the respective template file. Tasks such as accessing the PostgreSQL console or investigating NGINX logs are less user friendly. Users are now required to transition from the EC2 command line to the container command line for the relevant component, increasing the complexity of the process.
7 Future Work
Although we achieved our objectives for Tinker, we identified opportunities for further improvement. Specifically, there were two features we were interested in.
- Dashboard UI SQL queries: we’d like to incorporate an SQL editor directly into the dashboard UI. This feature would add a level of flexibility for the user beyond what a visual tool like the table editor could offer.
- Data Import and Export: we’d like the ability to import data from a csv file, and also export data to a csv file. Additionally, we’d like to provide a user-friendly database dump through the dashboard UI.
Thank you for taking the time to read about Tinker and the amazing journey it took us on!
8 Presentation
9 References
BaaS
- 3 myths about BaaS that you should drop
- The Case For Better Self-hosting Supabase Support
- Reasons Not To Use Firebase
Database
Companies: